XML Path Language (XPath) 2.0

|
This work is licensed under a Creative Commons
Attribution-NonCommercial-ShareAlike 2.5 License.
|
Abstract
The XML Path Language (XPath) is one of the most useful and frequently used languages in the are of XML technologies. In its version 1.0, it is used in technologies such as XSLT, XML Schema, DOM, and XML Tools. With XPath 2.0, the language has been greatly extended, the new version of XPath is the foundation for XSLT 2.0 and XQuery. XPath 2.0 provides support for regular expression matching, typed expressions, and contains language constructs for conditional and repeated evaluation.
Selecting Parts of XML Documents
- XML is a syntax for trees
- it defines a way for how trees can be exchanged
- XML technologies should provide support for working with trees
- when receiving trees, access to the tree should be easy (DOM)
- validating trees should be easy (XML Schema)
- mapping trees should be easy (XSLT)
- querying tree collections should be easy (XQuery)
- XPath is what regular expressions for text-based information
Making Selection Reusable
- Different XML technologies need selection
- XSLT needs it for selecting parts and manipulating them
- XML Schema needs it for applying identity constraints
- DOM needs it for extracting parts from an XML tree
- XQuery needs it for writing XML-oriented queries
- XPath was created to be reusable
- XML experts should only learn one selection language
- this knowledge can be reused when learning new technologies
- implementations can reuse code libraries
How XPath Evolved
- XSL was designed as the new XML stylesheet language
- XSL Transformations (XSLT) transform the input document
- XSL Formatting Objects (XSL-FO) is what they will transform it to
- XSLT was designed to work on arbitrary XML input documents
- XPath was turned into a standalone specification
- Complete overhaul for XSLT 2.0 and XQuery
Starting from the Infoset
- XPath operates on an abstract data model
- The Infoset is turned into an XPath node tree
- 11 infoset item types → 7 XPath node tree node types
- character items are merged into text nodes
- namespace declarations are no longer visible as attributes
What is Not in the XPath Tree
- The same things which are not in the Infoset
- the order of attributes in a start tag
- the types of quotes around attribute values
- character references and entities (
ü/ü → ü)
- And some more...
- namespace declarations are no longer visible as attributes
- notations and unexpanded entity references
Tree In / Selection Out
- XPath evaluates an expression based on a tree
- Where the tree comes from is out of XPath's scope
- The result of the evaluation is a selection
//img[not(@alt)] → select all images which have no alt attributecount(//img) → return the number of images/descendant::img[3]/@src → return the third image's src URIstarts-with(/html/@lang, 'en') → test whether the document's language is english
- Syntax errors may occur
XPath Expressions
- XPaths can be location paths
//ul/li
- XPaths can use functions
id('dret') - XPaths can be expressions yielding atomic values
substring-before(id('dret'), ' ') - XPaths can combine all of the above
count(//ul/li[starts-with(substring-after(., ' '), 'W')])
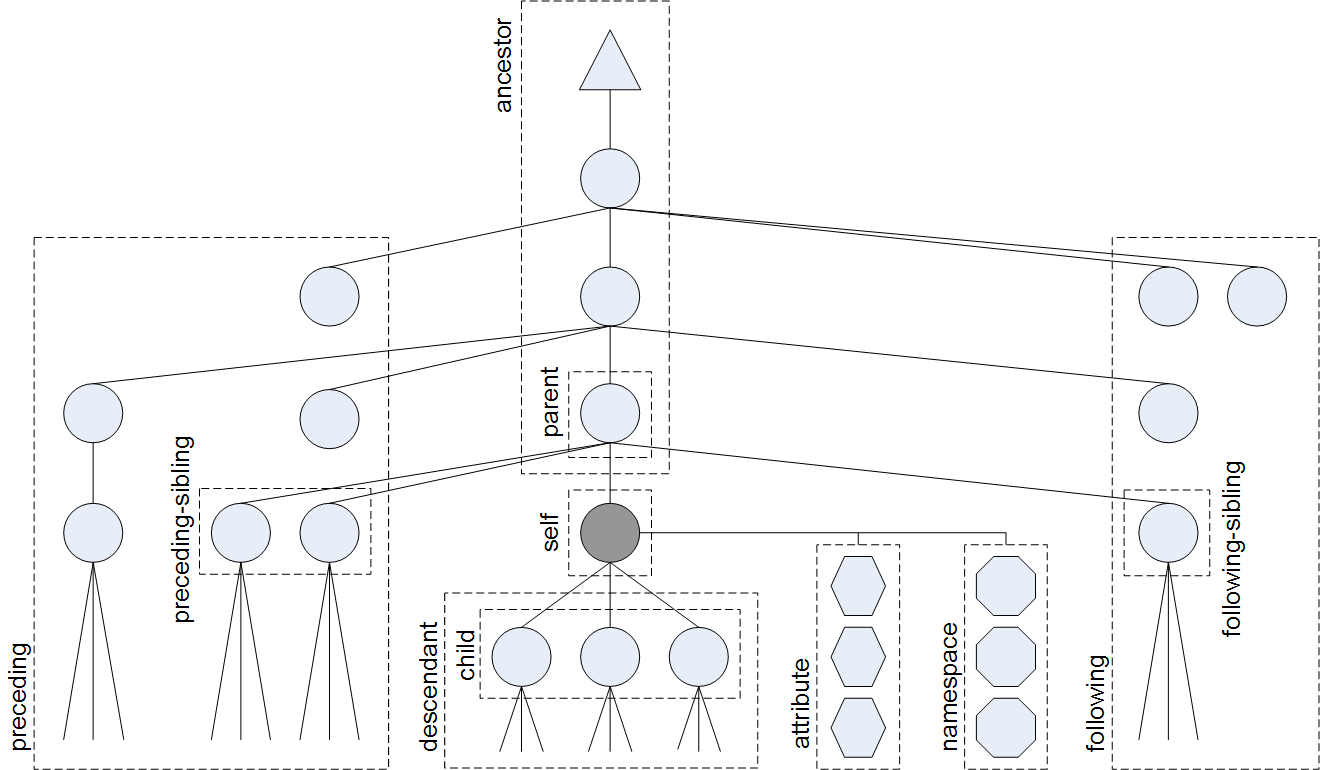
Axes
Easier to Understand
- XPath 2.0 provides better ways to write XPaths
- some constructs allow better ways of writing XPaths
- some constructs allow things previously impossible in XPath
- XPath usually is embedded in another language (XQuery, XSLT)
- even in XSLT 1.0, there was always a trade-off between XPath and XSLT
- with XPath 2.0, even more powerful XPaths can be implemented
- Finding a good balance between XPath and the host language is an art
- very complex XPaths can become almost undecipherable
- there is no final answer, coding styles vary based on language preference
<listing src="xlinked-class.xml" line="81-98"/>
string-join(tokenize( if ( exists(@encoding) ) then unparsed-text($fileuri, @encoding) else unparsed-text($fileuri), '\r?\n')[(position() ge number(tokenize(current()/@line, '\-')[1])) and (position() le number(tokenize(current()/@line, '\-')[2]))], '
')
Control Flow in XPath
- XPath 1.0 expressions
control flow
is based on predicates- the results of location path steps are filtered by predicates
- this can be used to
emulate
control flow - this technique is limited because it can only be applied to nodes
- XPath 2.0 introduces conditional expressions
- a condition is given which is interpreted as a boolean
- based on the result, either the then or the else part is evaluated
- the else part may not be omitted
if ( … ) then … else …
if ( @sex eq 'm' ) then 'Sir' else 'Madam'
if ( @sex eq 'm' ) then 'Sir' else if ( @sex eq 'f' ) then 'Madam' else 'Whatever'
Repeating Expression Evaluation
- Iteration repeatedly applies an expression to a sequence of items
- the notion of Sequences is central to this concept
- this requires variables for binding and evaluation
- Iterations clearly demonstrate the change in expressiveness
- they introduce functionality which previously was limited to host languages
for $… in … return …
for $i in //name return $i/last
for $i in //name return if ( exists($i/first) ) then $i/first else $i/last
Iterations vs. Location Paths
Testing Sequences
- Testing whether some or all items of a sequence satisfy a condition
- the notion of Sequences is central to this concept
- this requires variables for binding and evaluation
- Quantifiers are well-known from query languages
- some iterates over items and succeeds after the first success
- every iterates over items and fails after the first failure
- both constructs are good candidates for optimization
( some | every ) $… in … satisfies …
some $i in //*[@xlink:type='locator']/@xlink:href satisfies $i eq $query-uri
every $i in //li/@id satisfies //*[@xlink:type='locator'][@xlink:href=concat('#', $i)]
Major Changes
- XPath 1.0 has a very simple data model
- node sets:
//img[not(@alt)] - number:
count(//img) - string:
/descendant::img[3]/@src - boolean:
starts-with(/html/@lang, 'en')
- XPath 2.0 needs a more powerful model for its advanced functionality
- everything in XPath 2.0 is a sequence
- sequences can contain a mix of items of various types
- sequences cannot be nested (there are no sequences of sequences)
every $i in (11, 22, 33, 'string') satisfies string(number($i)) ne 'NaN'
Divide and Conquer
- Sequences are part of the XQuery 1.0 and XPath 2.0 Data Model (XDM)
- data models are separate entities from evaluation languages
- a data model can be reused in different evaluation languages
- XDM is far more complex than its predecessor, the Infoset
- XML Schema datatypes have been integrated into the data model
- Sequences allow more complex structures to exist
- Understanding the data model is key to understanding the language
- for simple XPaths, the mental model of XPath 1.0 works
- more advanced XPaths can only be understood when understanding XDM
Standalone
- XPath can be used in standalone XML tools
- editors provide XPath evaluation as
regular expressions for XML
- text-based searches in bigger XML documents are not a good idea
- Standalone tools are good for learning XPaths
- many tools support interactive evaluation
- seeing sequences visualized often is very helpful
for $i in (11, 22, 33, 'string') return ($i, number($i))
XQuery
- XML Query (XQuery) is built on top of XPath 2.0
- XPath allows constructing sequences based on documents
- XPath has no way of generating new document structures
- XQuery builds a query language around XPath
- the basic idea is to provide a language for constructing results from sequences
- ~80% of the complexity of XQuery are in XPath 2.0
declare variable $firstName external;
<videos featuring="{$firstName}"> {
let $doc := .
for $v in $doc//video, $a in $doc//actors/actor
where ends-with($a, $firstName) and $v/actorRef = $a/@id
order by $v/year
return
<video year="{$v/year}"> { $v/title } </video> }
</videos>
XSLT 2.0
- XSLT 2.0 is based on XSLT 1.0 and built on top of XPath 2.0
- XPath allows constructing sequences based on documents
- XPath has no way of generating new document structures
- XSLT focuses on transformations rather than queries
a query is a transformation is a query
- language preference is more a question of training and experience
- Many problems can be appropriately solved with both languages
- XQuery is favored by database people and by the big vendors
- XSLT 2.0 is favored by XML people who worked a lot with XSLT 1.0
- implementations could easily support both languages
Easy Transition
- XPath 1.0 users can start using XPath 2.0 right away
- apart from a few corner cases, the results will be the same
- XPath 2.0 has a huge set of functions and operators
- XML Schema types can be used, values can be cast
- Regular expressions are supported for working with strings