Web Technologies — Part I

|
This work is licensed under a Creative Commons
Attribution-NonCommercial-ShareAlike 2.5 License.
|
Abstract
The Web assumes an underlying network infrastructure providing a reliable, connection-oriented, flow-controlled end-to-end transport service. Based on such a network service, the Web's transport protocols move data between Web servers and browsers. The two most important protocols are the Hypertext Transfer Protocol (HTTP) for regular data transfers, and HTTP over SSL (HTTPS) for encrypted data transfers.
Web Server Service
- Web servers do more than just
deliver files
- They receive a request for acting on a resource
- Processing can mean anything, it is transparent for the client
- the result of processing yields a resource representation
Resource Identification
- The Web is centered around resources
- HTTP has been designed to manipulate resources
- HTTP provides methods for getting, putting, updating, and even deleting resources
- Resources are useful abstractions for interfaces
URI Schemes
URI = scheme ":" hier-part [ "?" query ] [ "#" fragment ]
- URIs in their general case are very simple
- the scheme identifies how resources are identified
- the identification may be hierarchical or non-hierarchical
- Many URI schemes are hierarchical
- it is then possible to use relative URIs such as in a href="../"
- the slash character is not just a character, in URIs it has semantics
[…] the URI syntax is a federated and extensible naming system wherein each scheme's specification may further restrict the syntax and semantics of identifiers using that scheme.
Uniform Resource Identifier (URI): Generic Syntax
, RFC 3986, January 2005
Query Information
- Query components specify additional information
- it is non-hierarchical information further identifying the resource
- in most cases, it can be regarded as
input
to the resource
The query component contains non-hierarchical data that, along with data in the path component […], serves to identify a resource within the scope of the URI's scheme and naming authority […].
Uniform Resource Identifier (URI): Generic Syntax
, RFC 3986, January 2005
Processing URIs
- Processing URIs is not as trivial as it may seem
- escaping and normalization rules are non-trivial
- many implementations are broken
- complain about broken implementations
- URIs are not just strings
- URIs are strings with a considerable set of rules attached to them
- implementing all these rules is non-trivial
- implementing all these rules is crucial
- application development environments provide functions for URI handling
Resources vs. Representations
- URIs identify resources
- abstractions which may not have physical representation
- Requesting a URI yields a resource representation
- should be an appropriate and useful manifestation of the abstraction
- Resources can have different representations
- in a well-designed environment, you should get what works best for you
Bad Service
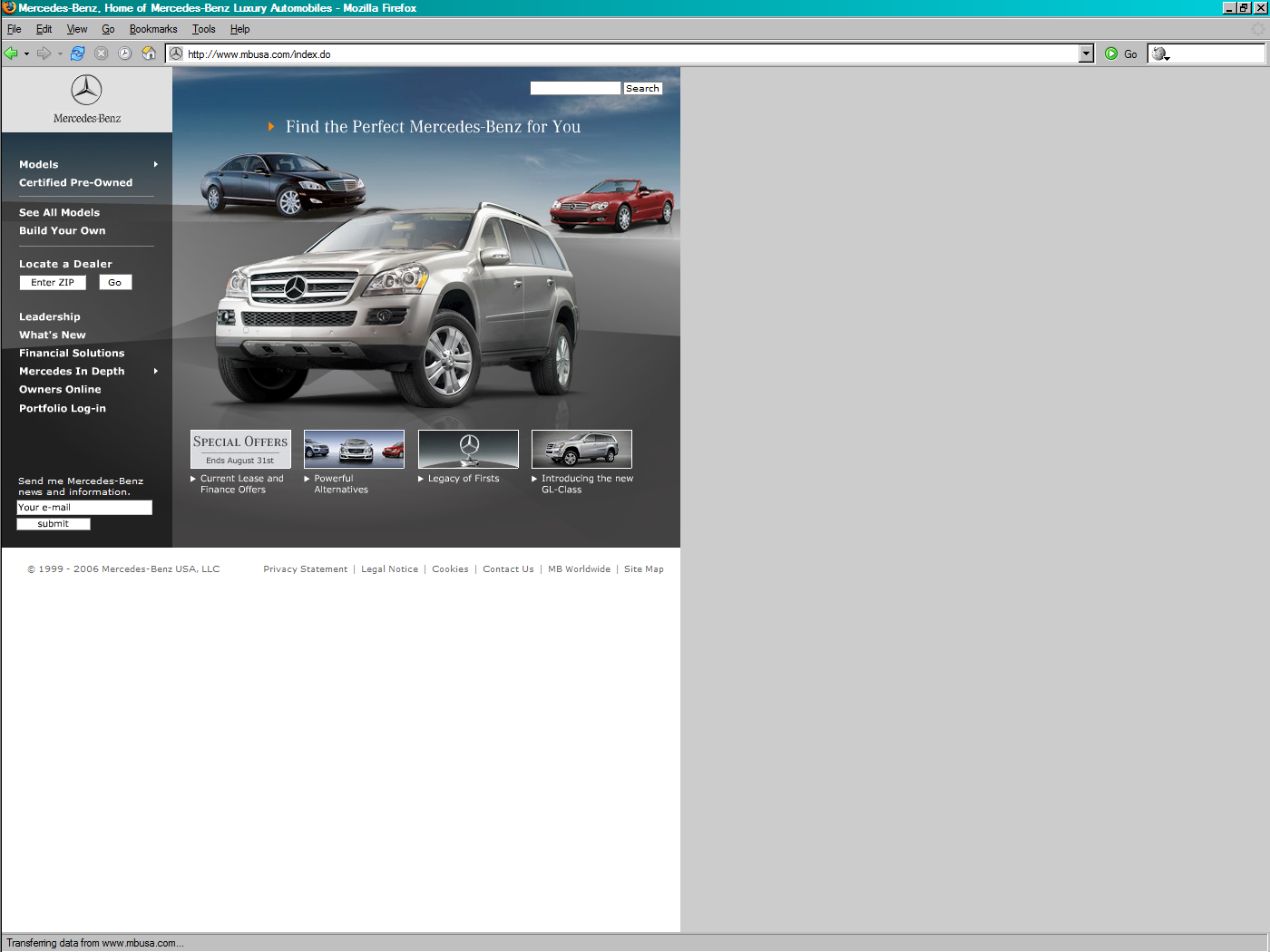
Popular Screen Resolutions
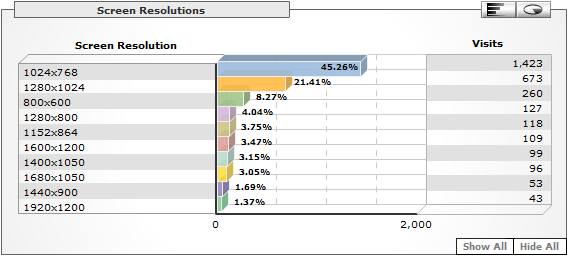
The Web's Protocol
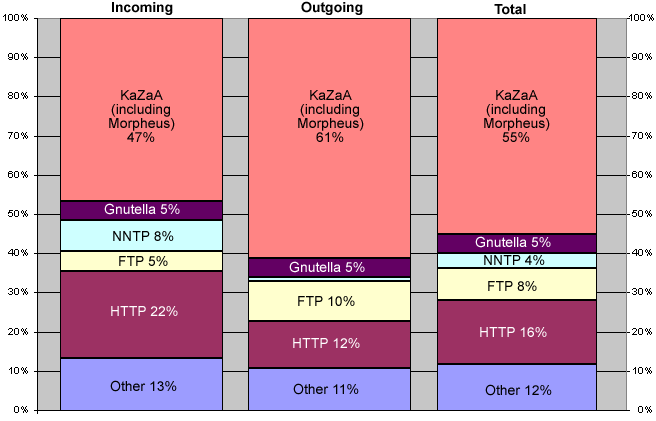
DNS & HTTP
The two basic protocols which every Web browser must implement are DNS access and HTTP. However, most operating systems provide an API for DNS access, so the browser can use this service locally and only has to implement HTTP. TCP (which is required as the foundation for HTTP) is usually provided by the operating system.
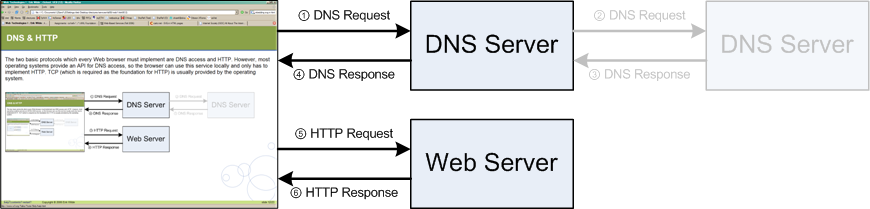
HTTP Messages
- HTTP needs a reliable connection
- the foundation for HTTP is the Transmission Control Protocol (TCP)
- DNS resolution yields an IP address
- open TCP connection to port 80 or port specified in URI (
http://pc-4528.ethz.ch:8080/)
- HTTP is a text-based protocol
- the connection is used to transmit text messages
- all HTTP messages are human-readable
- basic HTTP operations can be carried out by hand
start-line
message-header *
message-body ?
HTTP Header Fields
- Header fields contain information about the message
- general header:
Date as the message origination date - request header:
Accept-Language indicated language preferences - response header:
Server contains system information - entity header:
Content-Type specifies the media type of the entity
- HTTP defines a number of header fields
- unknown fields must be ignored (extensibility)
- unstandardized fields should use a
X-
prefix
- HTTP is about acting on these fields
- HTTP defines what HTTP implementations must or should do
HTTP Requests
- After opening a connection, the client sends a request
- the method indicates the action to be performed on the resource
- HTTP's most interesting methods are:
GET, HEAD, POST - other interesting methods are:
PUT, DELETE
- The URI identifies the resource to which the request should be applied
- absolute URIs are required when contacting Proxies
- absolute paths are required when contacting a server directly
- the URI may contain Query Information
- fragment identifiers are not sent (they are interpreted on the client side)
- The
Host header field must be included in every request
Method Request-URI HTTP/Major.Minor
[Header]*
[Entity]?
HTTP GET
- Retrieval action based on the URI
- maybe implemented by reading a file
- maybe implemented by processing a file (PHP)
- maybe implemented by invoking a process
- Semantics may change based on header fields
If-*: only reply with the entity if necessaryRange: only reply with the requested part of the entity
- Cacheability depends on header fields of the response
GET / HTTP/1.1
Host: ischool.berkeley.edu
HTTP Responses
- The server's response to interpreting a request
- the status code is given numerically and as text
2** for variations of ok
3** for redirections4** are different client-side problems (404: not found)5** are different server-side problems
- Header fields specify additional information
- information about the server
- information about the entity (media type, encoding, language)
HTTP/Major.Minor Status-Code Text
[Header]*
[Entity]?
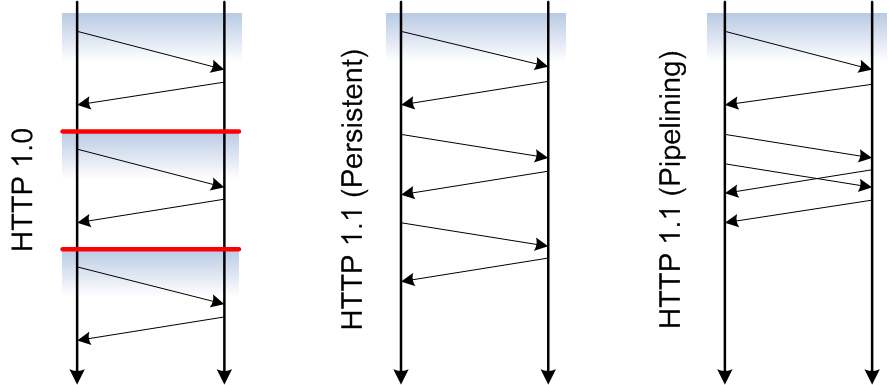
HTTP Performance
- HTTP/1.0 allowed one transaction per connection
- TCP connection setup and teardown are expensive
- TCP's slow start slows down the initial phase of data transfer
- typical Web pages use between 10-20 resources (HTML + images)
- typically, these resources are stored on the same server
- HTTP/1.1 introduces persistent connections
- the TCP connection stays open for some time (10sec is a popular choice)
- additional requests to the same server use the same TCP connection
- HTTP/1.1 introduces pipelined connections
- instead of waiting for a response, requests can be queued
- the server responds as fast as possible
- the order may not be changed (there is no sequence number)
HTTP Connection Handling
What is Content Negotiation?
- Negotiation between two HTTP peers
- resources may be available in different representations
- possible dimensions are language, graphics format, character encoding, …
- using one URI, it should be possible to get the
best
resource
- Negotiation requires knowledge about the resource user
- languages depend on humans reading pages
- graphics formats depend on the browser's functionality
- Content negotiation is a form of a Web-based service
- client request a URI and have some constraints
- using these constraints, the best representation should be served
- ideally, content negotiation should not be too expensive
Three Different Variants
- Server-Side Content Negotiation
- the server has a set of representations and information from the request
- the server returns the
best
representation based on the request
- Client-Side Content Negotiation
- the server responds with a list of different representations
- the client (browser or user) makes a choice and sends a second request
- Transparent Content Negotiation
- Caches act as in client-side negotiation and thus know the available representations
- Clients contacting the cache can be served by the cache as in server-side negotiation
Server-Side Content Negotiation
- Clients usually tell something about themselves
Accept, Accept-Charset, Accept-Encoding, Accept-Language- the server also knows their IP address
- the server may also use additional information (Cookies)
- The server needs to find the
best representation
- most easily by matching the request with available representations
- could also be implemented more dynamically by generating new representations
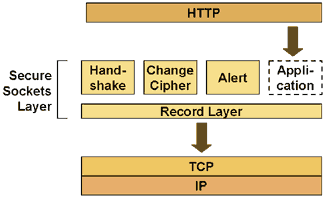
HTTP and Security
- HTTP sends clear-text messages
- listening to HTTP traffic is trivial
- information transferred via simple HTTP is public
- Making HTTP requires additional mechanisms
- S-HTTP was an attempt to define a secure version of HTTP
- HTTPS uses a secure communication layer underneath HTTP
- Encryption is done by a layer on top of TCP
- Secure Sockets Layer (SSL) is the protocol layer invented by Netscape
- Transport Layer Security (TLS) is the standardized Internet version
HTTP and SSL
Proxies
- HTTP often is end-to-end
- there is a direct connection between my browser and the server
- HTTP allows using proxies, which are HTTP intermediaries
- Proxies are used for security reasons
- a proxy is an important part of a firewall
- it hides the user's identity by acting on behalf of the user
- proxies are ideally suited for logging and filtering
- Proxies are used for performance reasons
- requests and responses can be cached, speeding up responses significantly
- caching depends on the ability to know when the cache is outdated
- HTTP enables proxies to validate their cached copies
Browsers & Proxies
A proxy is configured in the browser (manually or automatically), so that the browser sends all requests to the proxy instead of the target Web server. The proxy then forwards the request. Proxies can be chained, so that the requests and responses travel through a number of HTTP systems.

Firewalls
- Firewalls are used to protect computers
- protecting users from worms and viruses
- protecting servers from intrusion attacks
- firewalls analyze and block traffic based on complex rules
- A reverse proxy can be part of a firewall concept
- it is configured and maintained by the service provider
- it is a single access point through which HTTP traffic goes
- it is good because it bundles access control to servers behind it
- it is bad because it is a single point of failure
Web Server Service
- HTTP is much more than file transfer
- it is a protocol for the concept of resource manipulation
- it is a distinct step away from the API approach to building distributed systems
- HTTP servers can be configured to deliver good or bad service
- this is a question of how well they are configured on the HTTP level
- it is also a question of how good the Web design is
- both issues together are required to set up a good Web server
- Assignment 1 is an exercise in providing a good service
- very simple configuration of Apache
- this already is
cutting edge
! most servers are not properly configured…