(2) Abstract
The fundamental architecture of the Web only requires a Web server capable of answering HTTP requests on the server side. The question, however, is what that content server is serving when responding to requests. The content served by Web servers may come from files, from some form of managed more or less static content, or from dynamic processes. In this lecture, the idea of a Content Management System (CMS) or, more specifically, a Web Content Management System (WCMS), is introduced in a structured and disciplined way.
Content
in CMS
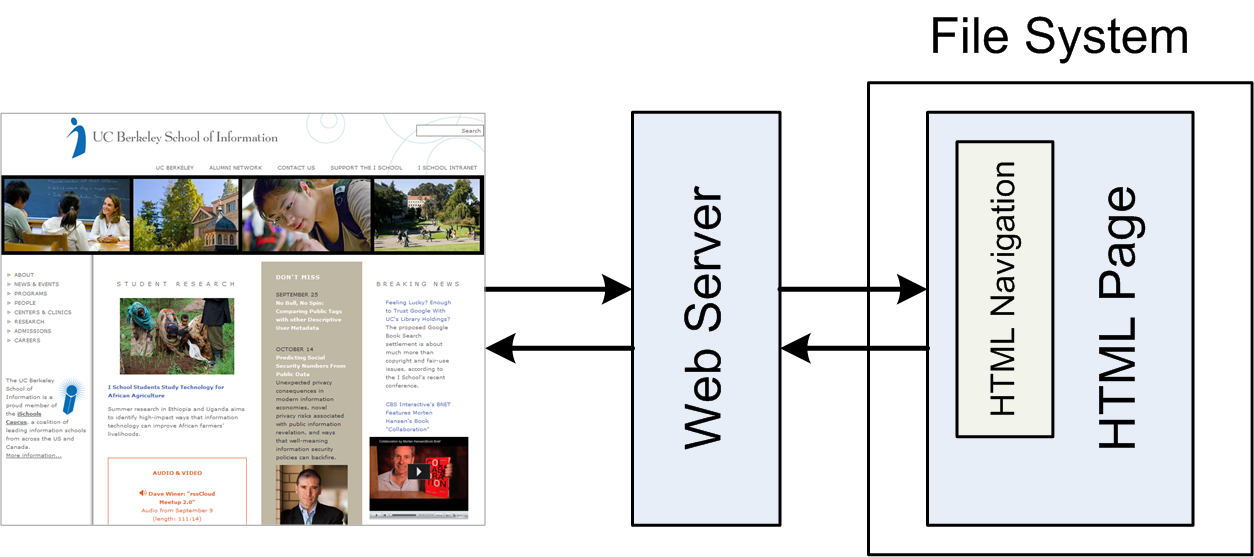
(8) Serving Content from Files
(9) The Rise of the CMS
- File-based content management works well for small sites
- simple site structure and small number of files
- redundant parts can be manually synchronized
- no software is required other than a Web server
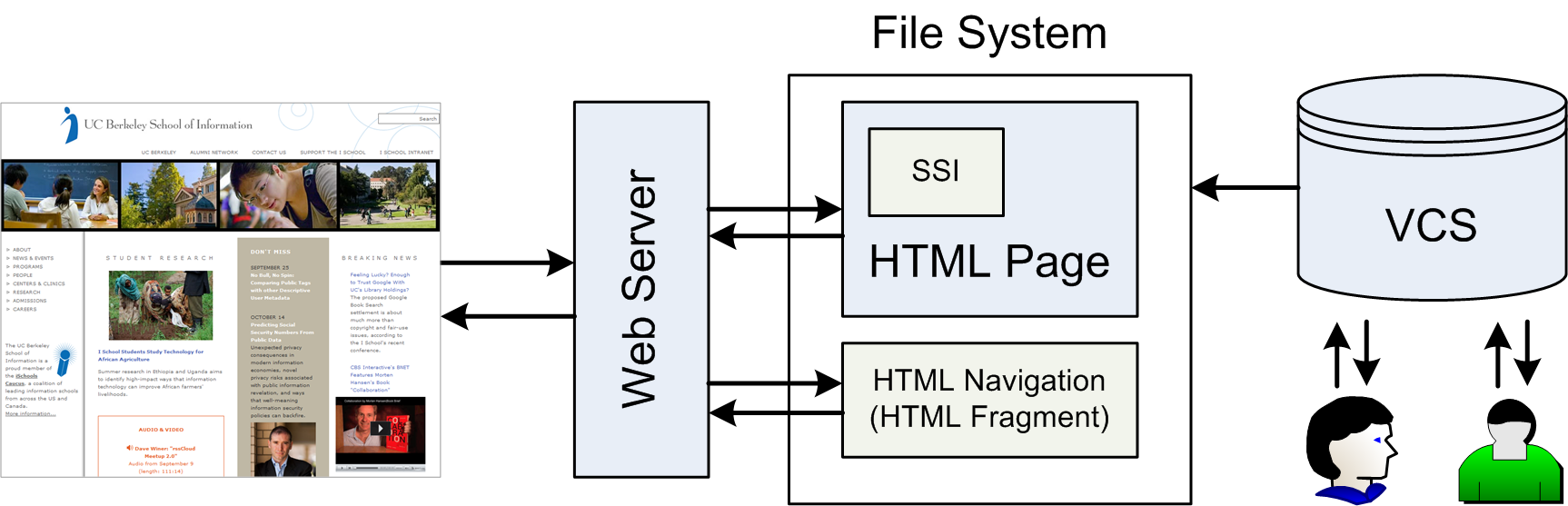
- Web servers soon developed rudimentary CMS functions ( [http://httpd.apache.org/docs/2.2/howto/ssi.html])
- rudimentary support is better than no support
- managing a non-trivial setup with SSI still is a challenge
- SSI allows includes but no backlinks and thus hides dependencies
- Content management is very similar to code management
- simple setups require no or little tool support
- serious projects need tools to manage dependencies and changes
(10) Serving Content from Files with SSI
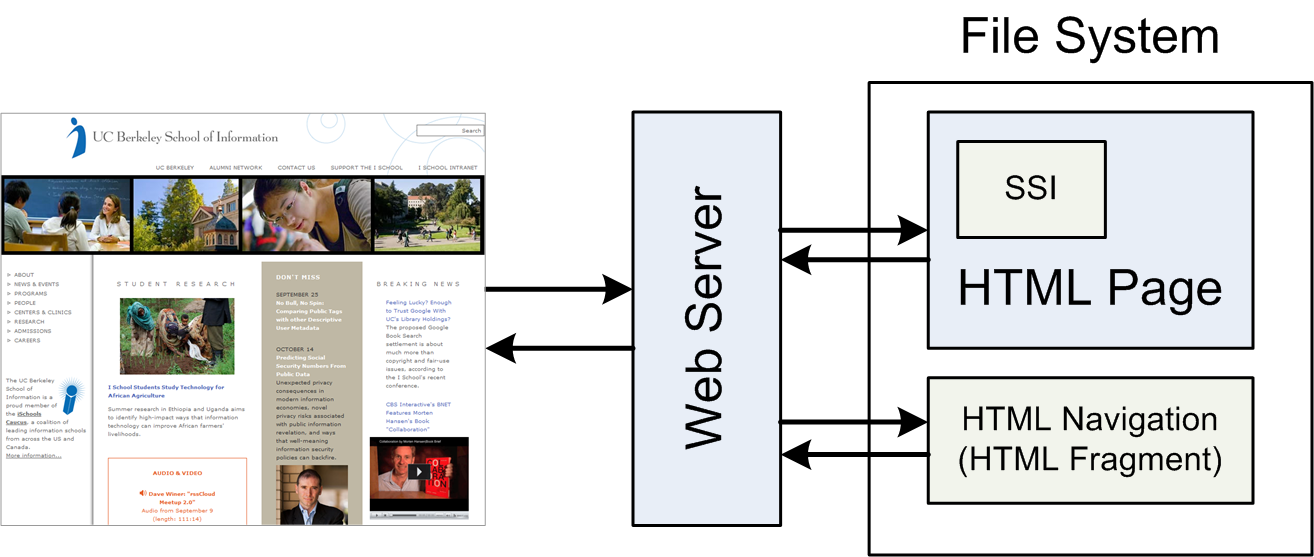
(11) Files (Opaque Chunks)
- All major operating systems have file systems
- Files are typically treated as opaque chunks of data
- Applications may have special knowledge of file contents
- Advantages of files:
- universally supported across major operating systems
- storage and user management comes for free
- all that is needed for a Web site is a Web server
- Disadvantages of files:
- content access requires file system access
- setting up parallel servers requires additional effort
- no support for managing structure, everything handcoded
(12) File Systems are Databases
- A file system is a simple hierarchical database
- it does not know data types and simply stores any content
- its structure is a tree with a few extra tricks (such as symlinks)
- Many scenarios have much more structured data models
- products, people, financial institutions all have complex data models
- content should be stored and queried based on these models
- Databases are better optimized for storing structured content
- better methods for structured storage and retrieval
- better strategies for managing large datasets
- sophisticated tools for access control, backup, and versioning
(13) Tables (Relational Model)
- Most widely used model for large collections of structured data
- Very mature products and many skilled people available
- The biggest advantage is that it is not hierarchical (no structure bias)
- Advantages of relations:
- well-understood model and maps well to existing data
- the non-hierarchical model allows views from different perspectives
- highly scalable solutions available
- Disadvantages of Relations:
- bad for sequences and variable structures (choices, repetitions, …)
- very bad for structured documents
(14) ER Model

(15) Ordered Trees (XML)
- XML [Extensible Markup Language (XML)] has a heritage of document processing
- XML tools can be used standalone and are widely supported
- XML and HTML have a very similar foundation
- XML has two built-in directions: hierarchy and ordered children
- Advantages of XML:
- maps well to HTML and XHTML
- well-suited for document-oriented content
- Disadvantages of XML:
- not good at representing non-tree data
- databases not as mature as relational products
(16) XML Content
The term Mixed content in XML refers to elements [http://www.w3.org/TR/xml/#sec-mixed-content]. What these elements do depends on the elements  , but the important point is that they are on the same level as the text nodes of the mixed content.
, but the important point is that they are on the same level as the text nodes of the mixed content.

(17) Directed Graphs (RDF)
- RDF is the metamodel of the Semantic Web [Semantic Web]
- Highly granular, less rigid than tables, less ordered than trees
- Advantages of RDF:
- any structure can be mapped to RDF triples
- support still limited but getting better
- Disadvantages of RDF:
- no model for document boundaries and self-contained units
- bad for sequences
- very bad for structured documents
(18) Choose a Matching Metamodel
- Content has some
inherent
metamodel properties- forcing that into a different metamodel is possible but unwise
- Using a metamodel which best matches a model is crucial
- if you have large collections of rigid and highly-structured data: Tables
- if you have structured documents with rich text: XML
- if you have fine-granular graph-structured data: RDF
- Mapping is always possible but has severe limitations
- things that work effortlessly in one metamodel may be awkward in another
- there is no such thing as
the one metamodel for all needs
- RDF's claim to be the one metamodel for everything is not backed by facts