XQuery 1.0 and XPath 2.0 Data Model (XDM)
XML Foundations (INFO 242)
Erik Wilde, UC Berkeley School of Information
2007-10-11
This work is licensed under a CC |
This work is licensed under a CC |
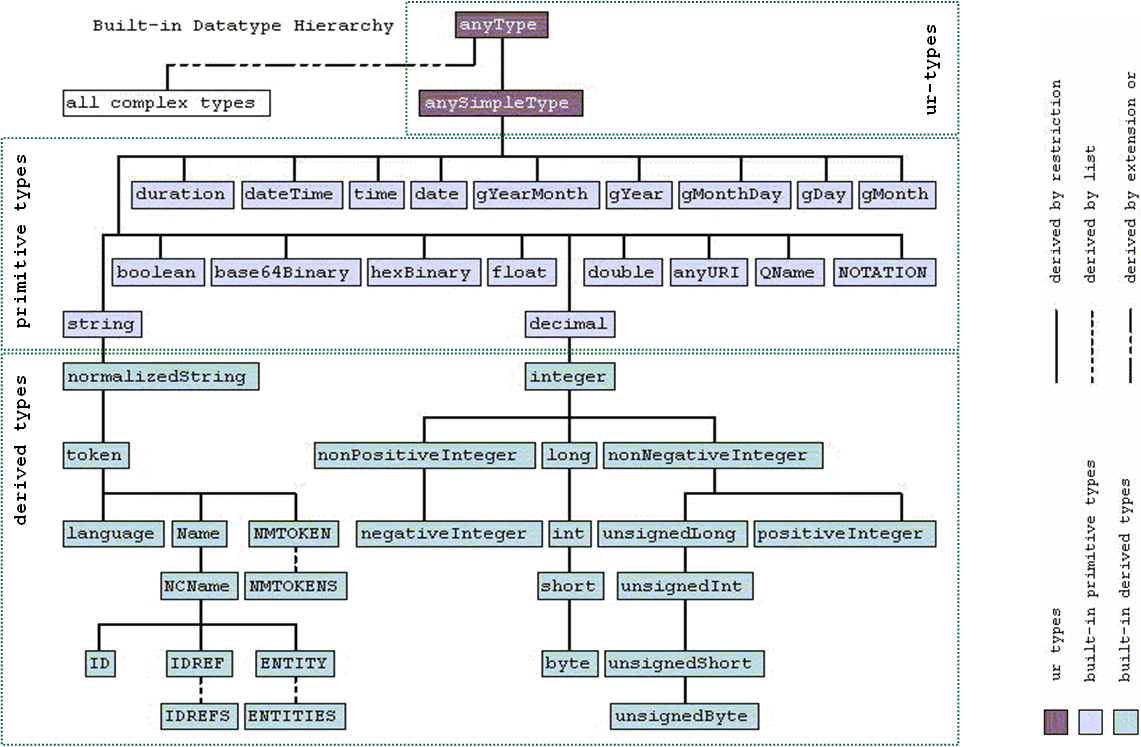
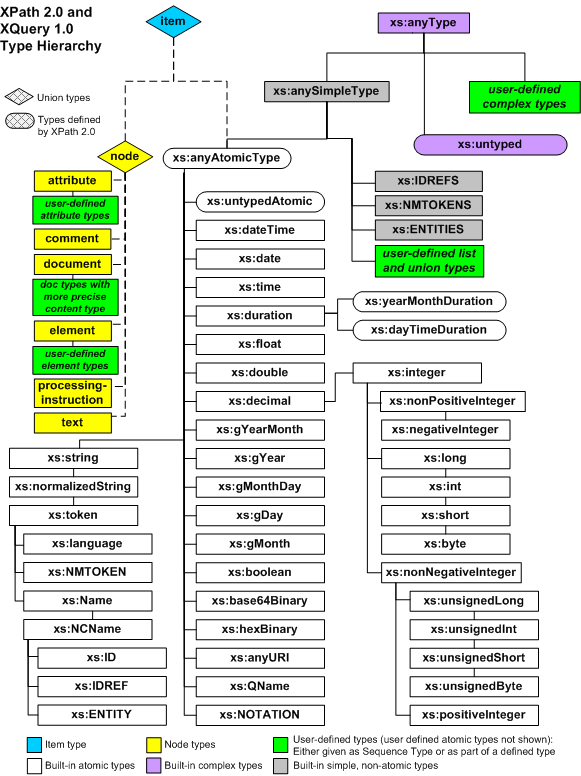
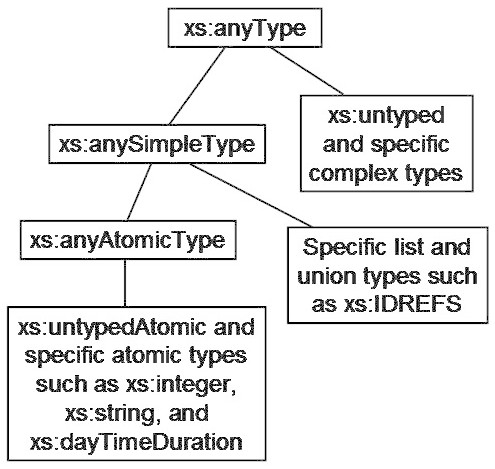
While XPath 2.0 syntactically is an extension of XPath 1.0, the underlying data model has changed quite radically. Instead of XPath 1.0's simple concept of four datatypes (node set, number, string, boolean), the XQuery 1.0 and XPath 2.0 Data Model (XDM) is based on sequences and allows much more sophisticated ways of data representation and manipulation. Furthermore, XDM includes the datatypes defined by XSDL, which results in an complex and powerful collection of built-in datatypes and operations on these datatypes.
//img[not(@alt)]count(//img)/descendant::img[3]/@srcstarts-with(/html/@lang, 'en')Sequences replace node-sets from XPath 1.0. In XPath 1.0, node-sets do not contain duplicates. In generalizing node-sets to sequences in XPath 2.0, duplicate removal is provided by functions on node sequences.(XDM)
= != < <= > >=
$X = $Y
some $x in $X, $y in $Y satisfies $x eq $y
eq ne lt le gt ge
is << >>
$a is $bis true only if both variables identify the same node
generate-id($a) = generate-id($b)
$a << $bis true if $a precedes $b in document order
$X = $Xis not always true
$X != 'test'and
not($X = 'test')are not the same
$X != 'test'is true if one item in $X is not equal to 'test'
not($X = 'test')is true if no item in $X is equal to 'test'
@mode != 'test'is false if there is no @mode!
$X = $Yand
$Y = $Zdoes not imply
$X = $Z
(1, 2),
(2, 3), and
(3, 4)illustrate this behavior
partial equality(one item must be equal)
empty(()) = true()
exists((1, 2, 3)) = true()
if ( exists(@email) ) then …
if ( empty(@email) ) then …
Set Operationson Sequences
sets(no duplicates, document order)
() | ()
sets(no duplicates, document order)
() intersect ()
sets(no duplicates, document order)
() except ()
deep-equal((1, 2, 3), (1, 3, 2)) = false()
((1, 2, 3), (4, 5, 6)) = (1, 2, 3, 4, 5, 6)
reverse((1, 2, 3, 4)) = (4, 3, 2, 1)
index-of((1, 2, 3, 1), 1) = (1, 4)
subsequence((1, 2, 3, 4, 5, 6, 7), 5, 2) = (5, 6)
insert-before(("one", "two", "four"), 3, "three") = ("one", "two", "three", "four")remove(("white", "white", "black", "white"), 3) = ("white", "white", "white")distinct-values((1, 2, 3, 1, 2, 6, 7)) = (1, 2, 3, 6, 7)
unordered((1, 2, 3, 4, 5)) = (3, 4, 1, 2, 5)
count((1, 2, 3, 4, 5, 6)) = 6
avg((1, 2, 3, 4, 5, 6)) = 3.5
max($seq) ge min($seq)
sum(1 to 42) = 903
42 instance of xs:integer
'2007-02-13' castable as xs:date
'2007-02-13' cast as xs:date
if ( $i castable as xs:… ) then $i cast as xs:… else ()
![//reference[starts-with(date/@value, '2004')]](img/question-mark.gif "//reference[starts-with(date/@value, '2004')]") )
)YYYY[-MM[-DD]] )topic-xml (ignore the @weight) ) )xref[@type eq 'updates']points to updated references (to their @name)
)), count both