XQuery 1.0 and XPath 2.0 Data Model (XDM)
XML Foundations [./]
Fall 2008 — INFO 242 (CCN 42572)
Erik Wilde, UC Berkeley School of Information
2008-10-21
![]() [http://creativecommons.org/licenses/by/3.0/]
[http://creativecommons.org/licenses/by/3.0/]
This work is licensed under a CC
Attribution 3.0 Unported License [http://creativecommons.org/licenses/by/3.0/]
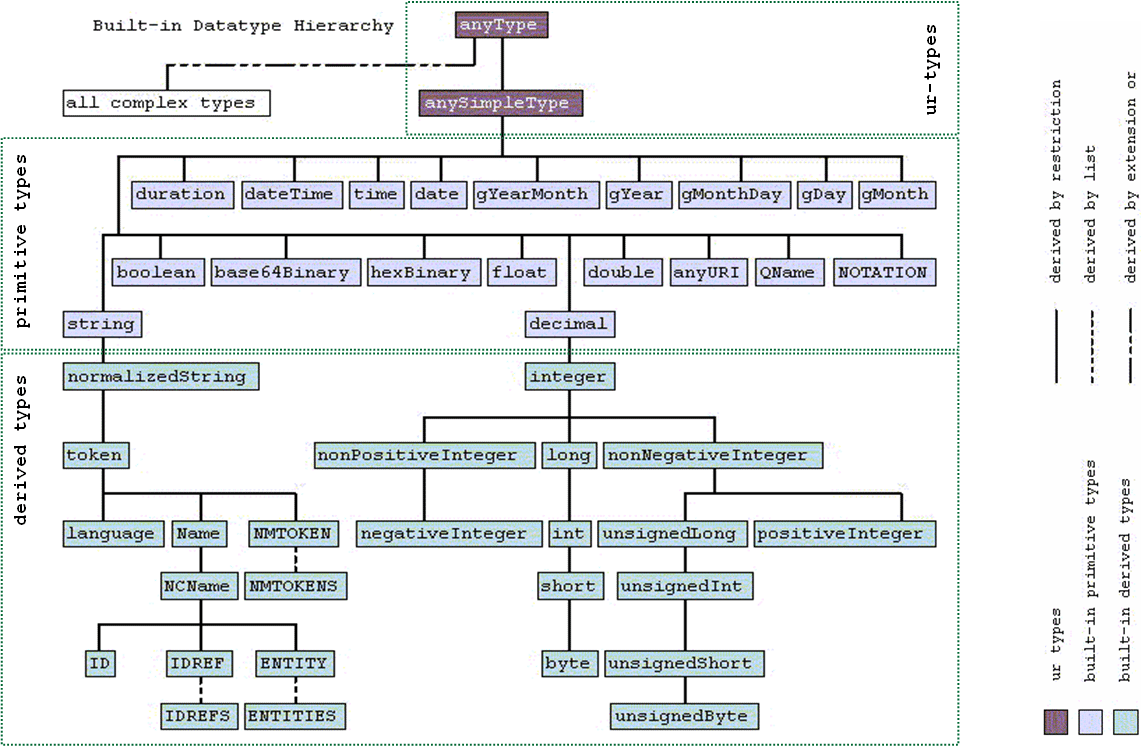
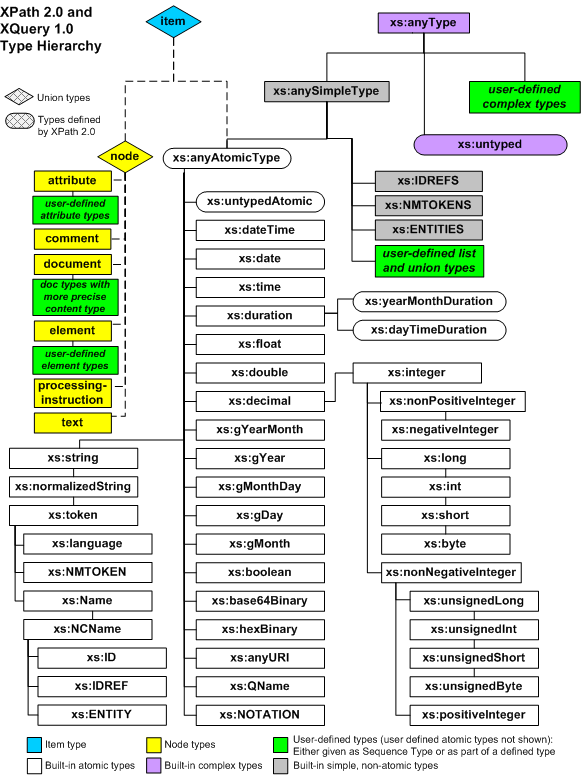
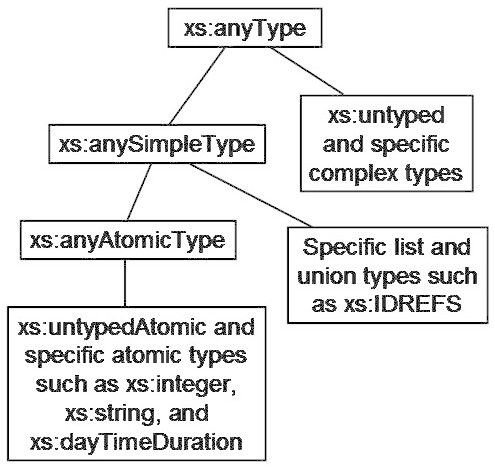
![//reference[starts-with(date/@value, '2004')]](img/question-mark.gif "//reference[starts-with(date/@value, '2004')]") )
)