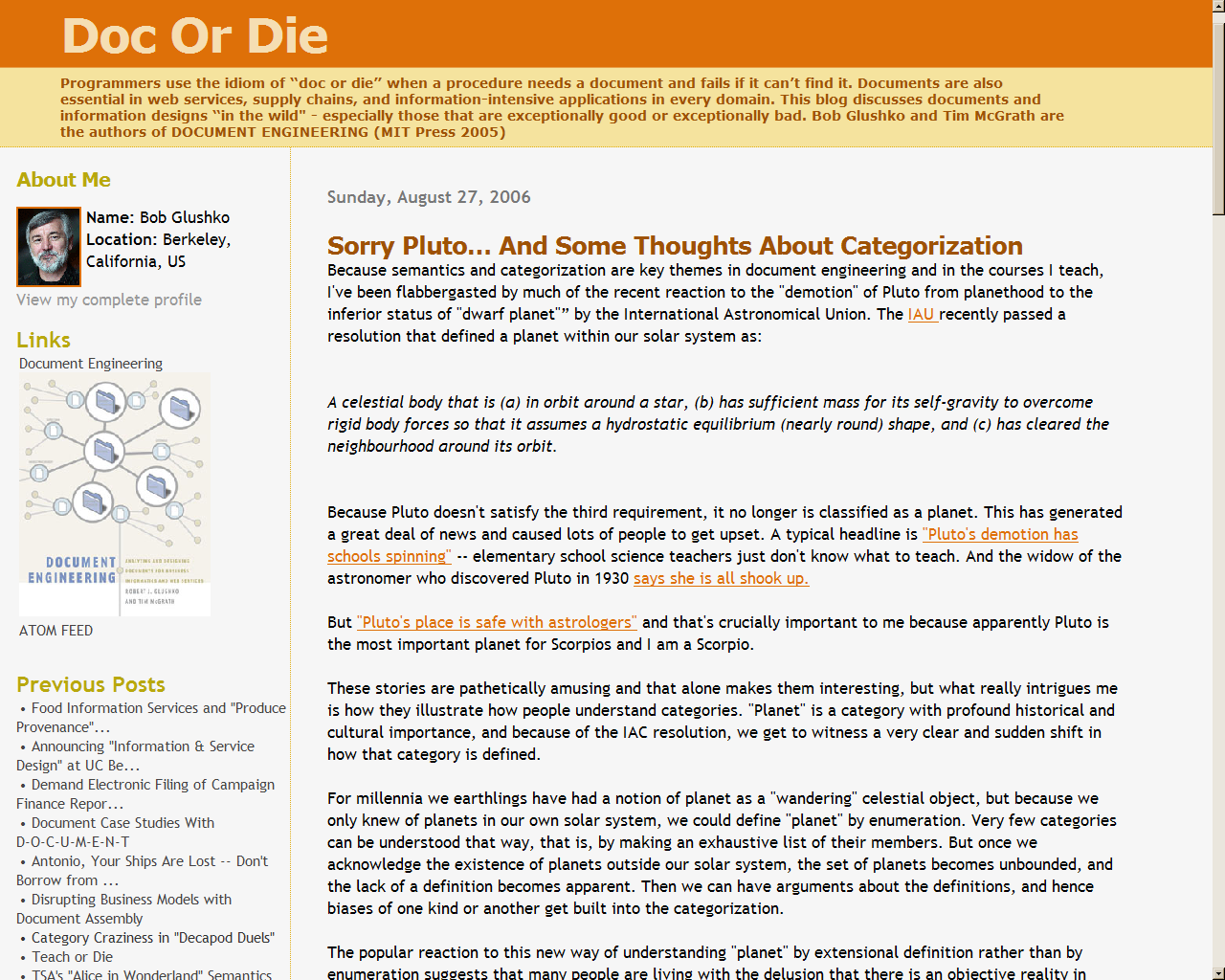
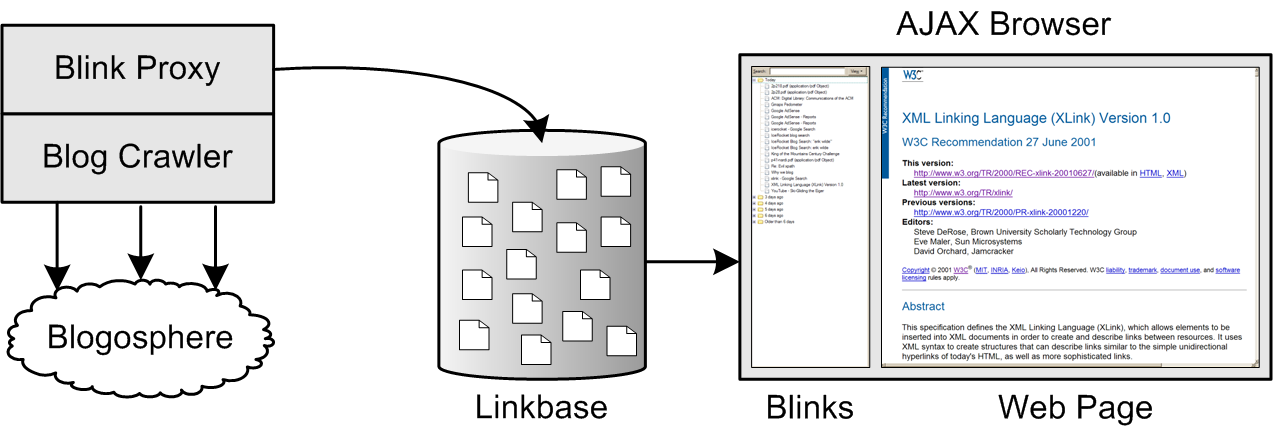
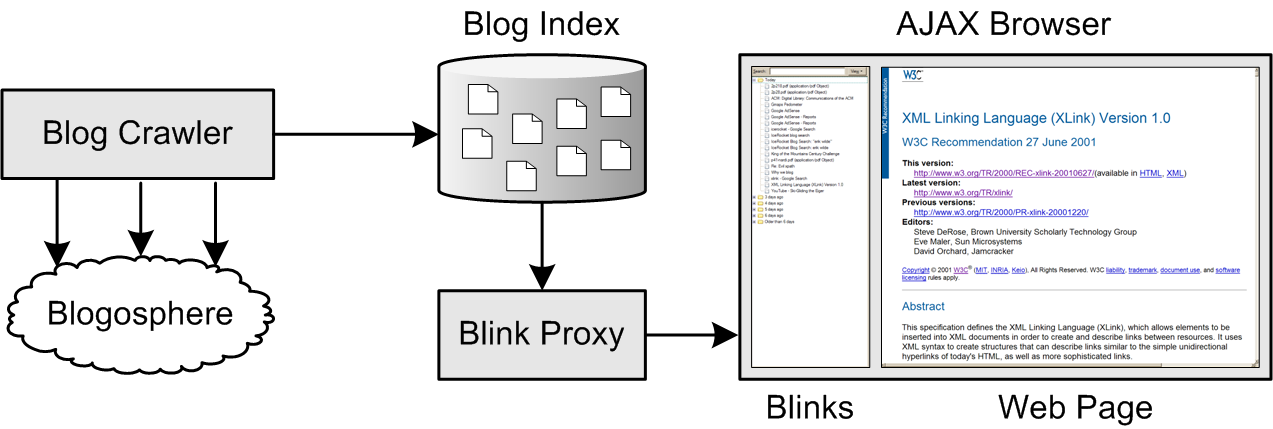
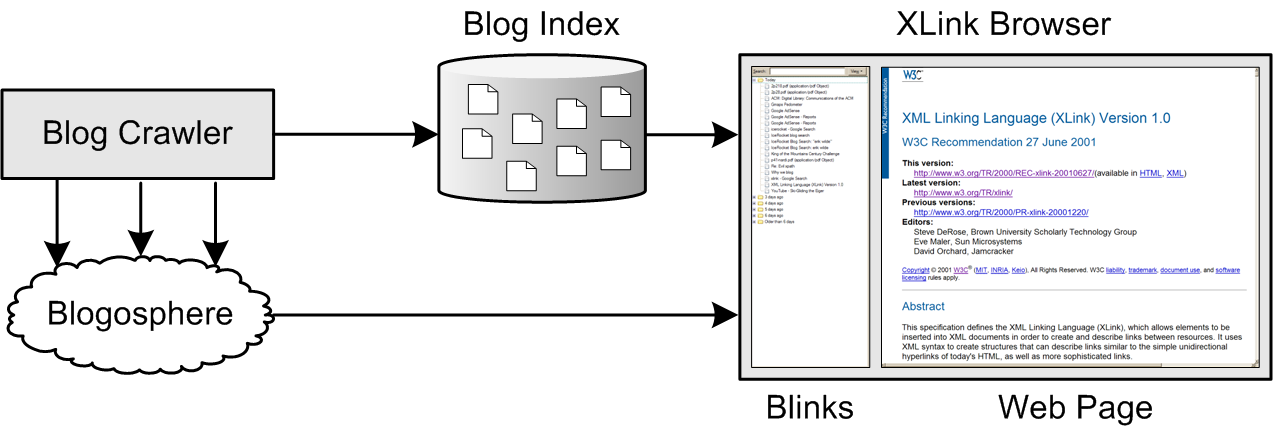
Abstract
Web 2.0 applications have become popular as drivers of new types of Web content, but they have also introduced a new level of interface design in Web development; they are focusing on richer interfaces, user-generated content, and better interworking of Web-based applications. The current foundations of the Web 2.0, however, are strictly imperative in nature, which makes it difficult to develop applications which are robust, interoperable, and backwards compatible. Using a declarative approach for Web 2.0 applications, this new wave of applications can be built on a more robust foundation which is more in line with the Web's style of using declarative methods whenever possible. We show a path how today's imperative Web 2.0 applications can be regarded as a testbed as well as a first implementation for a revised version of Web 2.0 technologies, which will be based on declarative markup rather than imperative code.